
- IC�ͺ�
��ҵ����
- ���֤����

- ��Ա���ͣ���ͨ��Ա
- ������

- �绰��18576232501
- �ֻ���18929337441
- ������
- �绰��18929337441
- �ֻ���18576232501
- ��ַ����������ǿ���ֵ�����㳡2002A
- E-mail��2931180544@qq.com
��Ʒ����
AIѵ�����ɻ�ȱ�Ĵ洢��HBM3 DRAM������
����ʱ�䣺 2023/4/24 9:24:11 | 134 ���Ķ�
SK����ʿ���շ���quan���״�ʵ�ִ�ֱ�ѵ�12����ƷDRAMоƬ���ɹ�������zui������24GB��HBM3 DRAM�²�Ʒ��

ͼԴ��SK����ʿ
Ŀǰ��������quan��ͻ���˾�ṩ��24GB HBM3 DRAM��Ʒ���ڽ���������֤��Ԥ�ƴӽ����°������������г���������HBM3 DRAM��zui�������Ǵ�ֱ�ѵ�8����ƷDRAMоƬ��16GB�������Ƕѵ��������������ϣ��˴η�������Ʒ��������������
HBM���ߴ����洢�����Ǹ�ֵ�������ܴ洢������ֱ�������DRAMоƬ��ĿǰSK����ʿ��HBM�г�����ling�ȵ�λ��Լ��60%-70%�ķݶ

ͼԴ��SK����ʿ
SK����ʿ��2013���״ο���HBM DRAM��diһ������Ʒ�������HBM2���ڶ�������HBM2E������������HBM3�����Ĵ�����˳��������ȥ��6�£�SK����ʿ������HBM3����NVIDIA H100Tensor CoreGPU����������ټ��㣬SK hynix��2022��������ȿ�ʼ�����������������ChatGPT��huo����HBM������������ôSK����ʿ����Щ����������HBM�������أ����½��SK����ʿ��λ����zhuan�ҵķ�������һЩ�����
ѵ��������ƥ������ܴ洢
ѵ��GPT-3��Megatron-Turing NLG 530B�ȳ�������ģ����Ҫ������������ٶȳ����������ٱ���������������ChatGPT��ѵ����ChatGPT�˹���������ģ�͵ı������Transformer�ܹ�������ܹ�ͻ���˴�ͳ��ѭ����������RNN���ͳ���ʱ����������LSTM���ľ����ԣ��ܹ��ڴ��ģ���ݼ��Ͻ��и�Чѵ����Ϊ��ʵ�ָ�Чѵ�����㣬����Ҫ����֮ƥ��ĸ����ܴ洢��
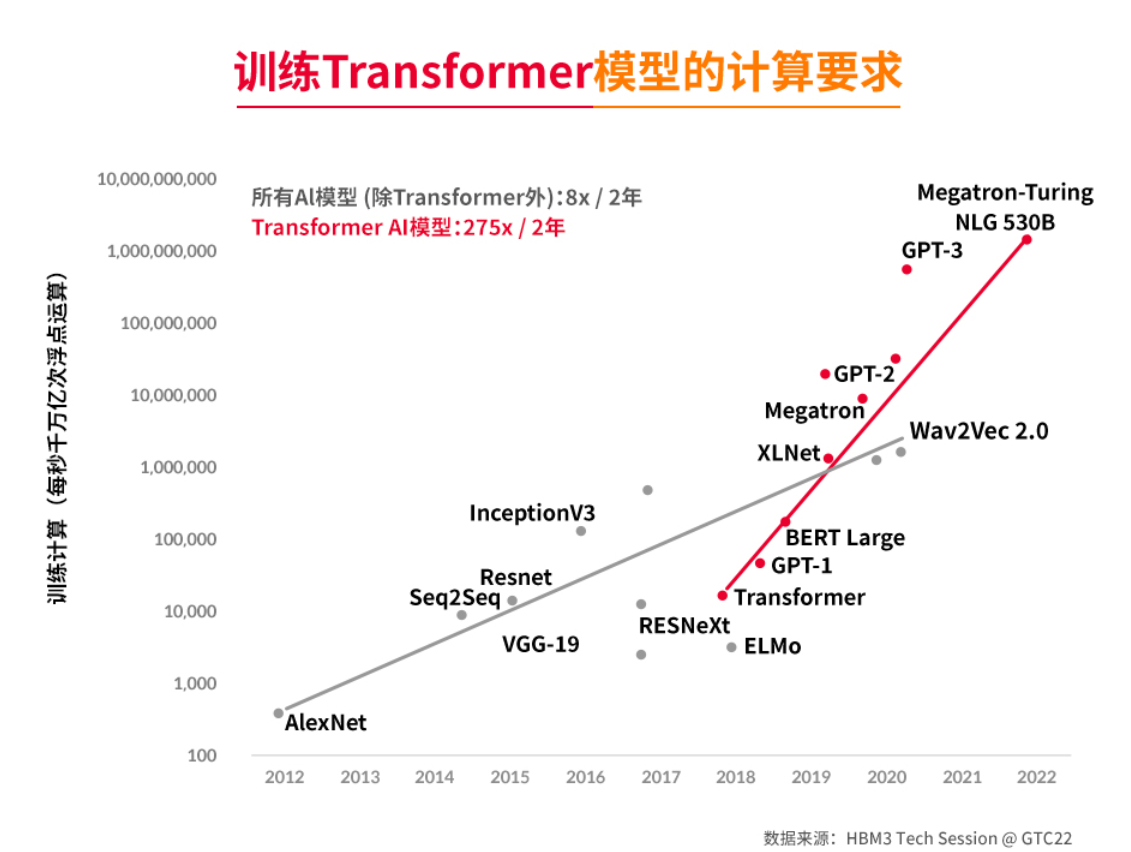
ͼԴ��SK����ʿ
SK����ʿ��2021��10���Ƴ�quan����HBM3������2022��6��ʵ���������ݽ��ܣ��ÿ�HBM3ÿ�����Ŵ������ʴ�6.4Gbps��1024λ���ӿڣ�zui�ߴ����ɴ�819GB/s����HBM2E��460GB/s����Լ78%��16Gb�ں��ܶȡ�jian�˵�TSV��ֱ�ѵ�������������ϵͳ�Ը����ܶȵ�Ҫ�ü�����ʵ��12��ѵ��ڴ������壬�Ӷ�ʵ��zui��24GB��װ�ܶȡ�HBM3�䱸On-die ECC�������룩�ɿ��Թ��ܣ�����������;������ݴ��Ӷ���SoC��DRAM֮��ʵʱ���亣�����ݡ�
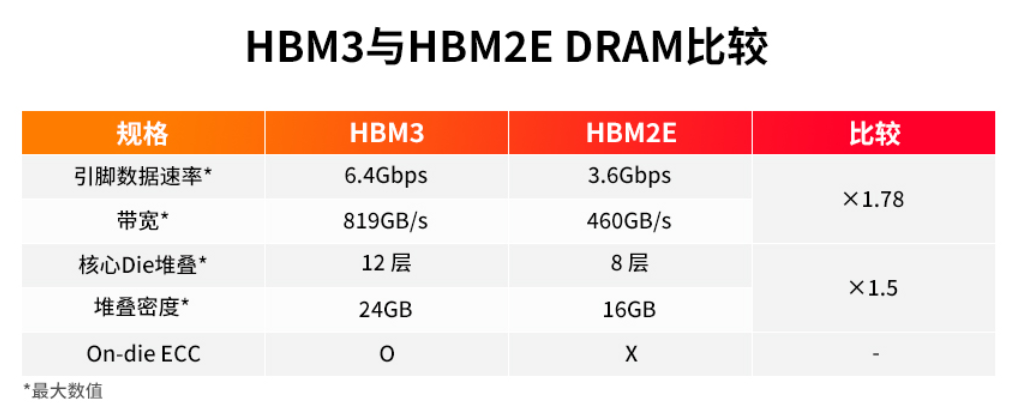
ͼԴ��SK����ʿ
�Ƚ��ķ�װ����
�˴��²�Ʒ�������Ƚ���Advanced��MR-MUF��TSV������SK����ʿ��ʾ��ͨ���Ƚ�MR-MUF������ǿ�˹���Ч�ʺͲ�Ʒ���ܵ��ȶ��ԣ�������TSV������12��������оƬ��40%�ĵ�ƷDRAMоƬ��ֱ�ѵ���ʵ������16GB��Ʒ��ͬ�ĸ߶ȡ��������Ҳ��SK����ʿ�Ƚ���װ��������Ҫ��ɡ�
���������Ƚ�MR-MUF����������SK����ʿ��guan��������MR-MUF��Mass Reflow Molded Underfill, ��������ģ�Ƶײ���䣩���뵼��оƬ�����ڵ�·�ϣ����ڶѵ�оƬʱʹ�á�EMC (Epoxy Molding Compound, Һ̬������֬ģ���ϡ����оƬ֮���оƬ����֮���϶�Ĺ��ա������µĹ�����Ҫ�DZ�֮ǰ��NCF�����������˺ܴ���������ǰ��NCF��������оƬ֮��ʹ�ñ�Ĥ���жѵ�����NCF��ȣ�MR-MUF�����ʸ߳��������ң������ٶȺ����ʶ���������
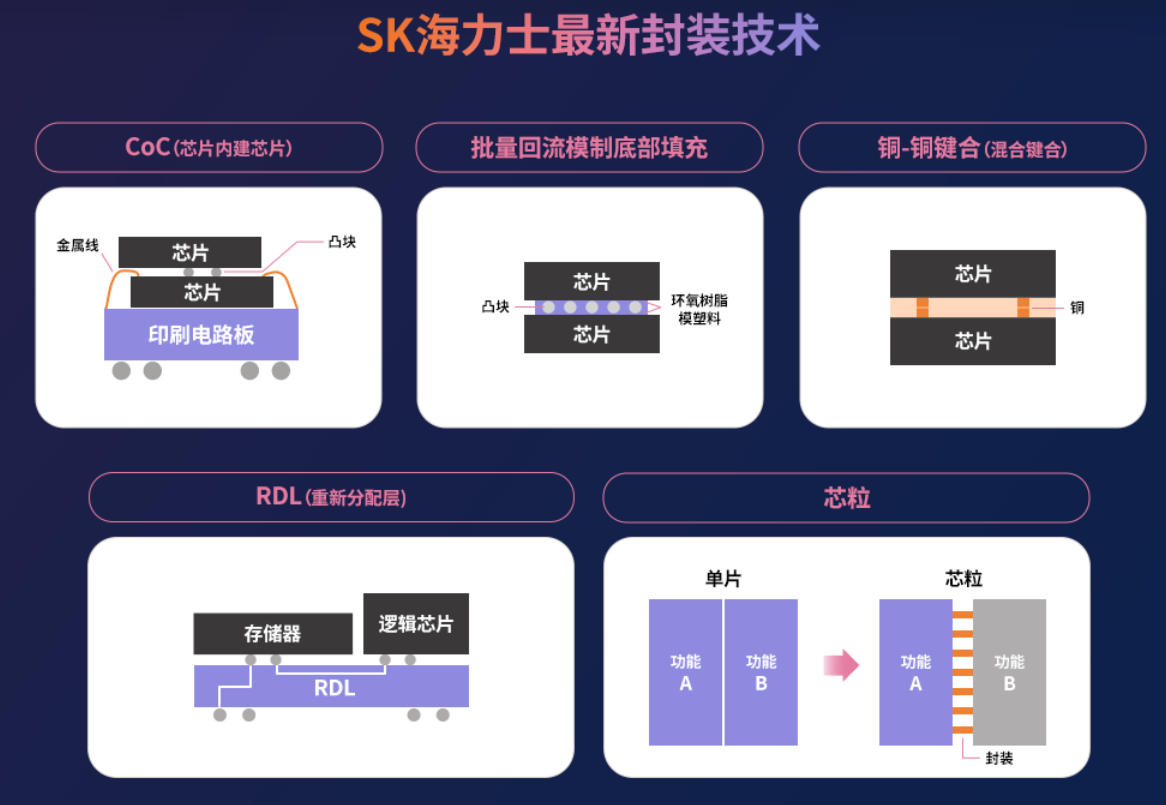
��һ����TSV��Through Silicon Via�� ��ͨ��������TSV��������DRAMоƬ������ǧ��ϸ�Ŀף���ͨ����ֱ��ͨ�ĵ缫��������оƬ���Ƚ���װ���������ּ����Ѿ���Ϊһ������DRAM���ܺ��ܶȵ���Ҫ�ֶΣ�����Ӧ����3D-TSV DRAM��HBM��

ͼԴ��SK����ʿ
HBM��Ҫ�����ֲ�SoC�ߴ������������洢��zui�������Ӧ����֮��Ĵ���ȱ�ڡ�SK����ʿzhuan�ұ�ʾ���ر�����AIӦ���У�ÿ��SoC�Ĵ���������ܶ��ᳬ����TB/s�����dz������洢��������ġ��������3200Mbps DDR4 DIMM�ĵ������洢��ͨ��ֻ���ṩ25.6GB/s�Ĵ�������ʹ�Ǿ���8���洢��ͨ����CPUƽ̨�����ٶ�Ҳֻ�ܴﵽ204.8GB/s����Χ�Ƶ���SoC��4��HBM2�ѵ����ṩ����1TB/s�Ĵ��������ݲ�ͬ��Ӧ�ó���HBM�ȿ��Ե����������棬Ҳ������������洢�е�diһ�㡣
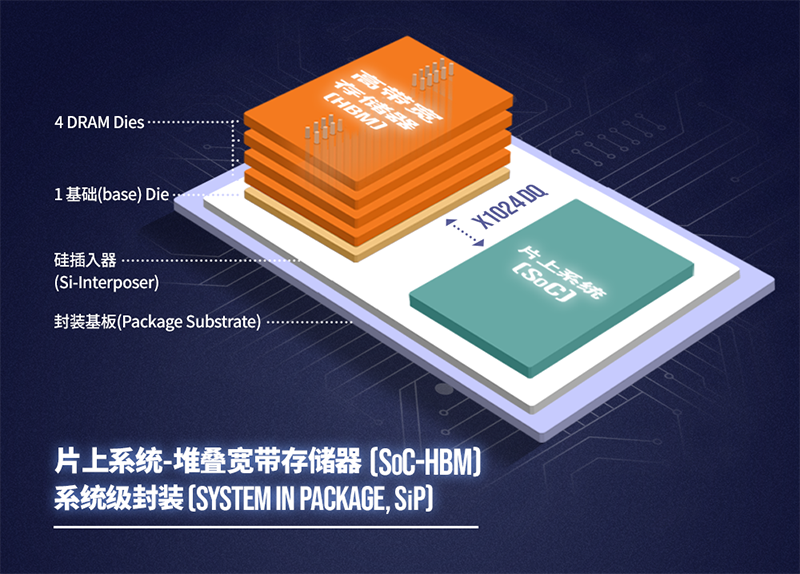
ͼԴ��SK����ʿ
ʵ���ϳ���GPU������HBM֮�⣬CPUҲʵ���˷�װHBM��ȥ��ף�Ӣ�ض�����ʽ�Ƴ���quan�����䱸 HBM �ڴ�� x86 CPU����Intel Xeon Max ϵ�С�������ͼ���ܣ�������64 GB��HBM2e �ڴ棬��Ϊ4��16 GB�ļ�Ⱥ�����ڴ����Ϊ1 TB / s��ÿ���ں˵�HBM������1 GB��

ͼԴ��Intel
��ǰHBM�ļ���������Ҫ�����ٶȡ��ܶȡ����ġ�ռ��ռ�ȷ����������SK����ʿͨ����������������ʡ�I/O����λ���ȷ�ʽ�������ʣ�ͨ����չDie�ѵ������������ѵ��߶ȣ��Լ�����he��Die�ܶ����Ż��ѵ��ܶȡ�ͨ�������ڴ�ṹ�Ͳ���������zui���ȵؽ���ÿ������չ��jue�Թ��ģ�Ϊ��ʵ�����ڴ�Die�ߴ�zuiС��������ͨ���ڲ��������������ߴ����������Ӵ洢��Ԫ�������ܡ�
��
��Ȼ���˹����ܡ��������ĵ�Ӧ�û�������HBM�������ӳɱ�������HBM��ƽ���ۼ�������DRAM��������ǰ������ChatGPT��������HBM�ļ۸����ˮ�Ǵ��ߣ���Ϣ��ʿ�ƣ�������zui�ߵ�DRAM���HBM3�ļ۸��������屶����������һ�г�ǰ��Ҳ����DRAM�洢����Ͷ�뼼���Ͳ�Ʒ�Ķ�����